If you’ve added Docker support to a project through Visual Studio you know that a Dockerfile is automatically created for you. Some things in this file are not very intuitive and took me a while to figure out, so I decided to document my findings and share them with the community. This is all based on my research and understanding, so if anyone knows better feel free to chime in. Also, I assume you have a basic understanding of what the commands in a Dockerfile do, the main purpose of this post is to explain the whys.
I’ll start by creating a .NET Core Console app called DockerConsoleApp and adding Docker support by right clicking on the project in Solution Explorer and selecting Add -> Docker Support (choose Linux or Windows depending on the kind of containers that your Docker daemon is configured to use).

How to add Docker Support to your project
Your solution should now have a docker-compose project, and your console app should now have a Dockerfile that looks like this (at least as of the time of writing; I’ve seen it change a couple of times in the past couple of months):
FROM microsoft/dotnet:2.0-runtime AS base
WORKDIR /app
FROM microsoft/dotnet:2.0-sdk AS build
WORKDIR /src
COPY DockerConsoleApp.sln ./
COPY DockerConsoleApp/DockerConsoleApp.csproj DockerConsoleApp/
RUN dotnet restore -nowarn:msb3202,nu1503
COPY . .
WORKDIR /src/DockerConsoleApp
RUN dotnet build -c Release -o /app
FROM build AS publish
RUN dotnet publish -c Release -o /app
FROM base AS final
WORKDIR /app
COPY --from=publish /app .
ENTRYPOINT ["dotnet", "DockerConsoleApp.dll"]
Obviously, the directory and file names (DockerConsoleApp in the example above) will depend on the name of your project.
Let’s split the analysis into the four stages defined in this file (base, build, publish and final) but I’ll tackle them from most-to-least obvious or complicated. So let’s start with the publish stage.
Publish stage
FROM build AS publish
RUN dotnet publish -c Release -o /app
The first line indicates that this stage depends on the build one, but that doesn’t prevent us from easily explaining what happens here. The one thing that’s worth noting is that the build stage has a copy of our application’s source code, and so RUNning dotnet publish in this stage does exactly what it sounds like: it builds our code (using the Release configuration specified with the -c parameter) and publishes the output to the /app directory in the image (specified with the -o parameter). Not much else to say here, so let’s move on.
Final stage
FROM base AS final
WORKDIR /app
COPY --from=publish /app .
ENTRYPOINT ["dotnet", "DockerConsoleApp.dll"]
This is the easiest stage to figure out. First off, it is based on the base stage, which in fact does nothing. “Why does it exist, then?” you might ask? We’ll get to that. What matters now is that the base stage depends on the official microsoft/dotnet:2.0-runtime docker image from Microsoft, which as its name implies contains the runtime bits to run (but not build) .NET Core applications (in particular console applications, ASP.NET Core applications are a slightly different story). This stage produces the final image that we’d publish to a repository so we want it to be as small as possible, making the 2.0-runtime image the best fit.
Lines 2 to 4 just move to a particular directory in the Docker image, copy the output of the publish stage (which is all that we need to run our app), and define the command to be executed when starting a container based on this image.
Build stage
FROM microsoft/dotnet:2.0-sdk AS build
WORKDIR /src
COPY DockerConsoleApp.sln ./
COPY DockerConsoleApp/DockerConsoleApp.csproj DockerConsoleApp/
RUN dotnet restore -nowarn:msb3202,nu1503
COPY . .
WORKDIR /src/DockerConsoleApp
RUN dotnet build -c Release -o /app
This is the most interesting stage in terms of the lessons it teaches. For starters we see that this stage is based on the microsoft/dotnet:2.0-sdk image in contrast to the microsoft/dotnet:2.0-runtime image used by the final stage above. The SDK image is signifcantly bigger (1.74GB VS 219MB) because it has everything required to build our code. The size comparison should make it clear why we want our final image to be based on the 2.0-runtime image and not the 2.0-sdk one.
The actual work done in this stage starts with copying the .sln and the .csproj files to the image. In this case it’s only one .csproj, but if your project depends on other projects in the solution, you’d see one COPY line per .csproj file. Then we run dotnet restore, and finally copy all of the source code (which I should note, overwrites the .sln and .csproj files that were copied earlier) before running dotnet build to compile our application.
So, if the last COPY takes care of the .sln and .csproj files, why are we “cherry-picking” them into the image by hand?
The answer is Docker’s build cache. Docker generates a layer each time it runs any command from a Dockerfile, and tries to reuse them as much as possible. Before running any command, it checks if it has run it before with the same current state (i.e. from the same current layer) and if it believes that running it again would result in the exact same result, then it just grabs that resulting layer from its cache; otherwise it executes the command and foregoes using the cache for any additional commands for the rest of that build. For ADD and COPY commands it uses a hash of the contents of the files to determine if it can use the cache, while for all other commands (like RUN) it just looks at the command string itself.
It should be clear that we want to leverage this cache as much as possible so building our Docker image is fast. One key insight towards this goal is that source code files change pretty much all the time, but not all steps of building our application actually need them. Another way of thinking about this is: when you bring your source code files into the image, you’re pretty much guaranteeing that Docker can’t henceforth use its layer cache, so before you do that you should try to perform as many build steps as possible in the hopes that at least those will be able to leverage the layer cache. The more “static” (deterministic) those build steps, the better their chances of actually being able to use the cache.
dotnet restore is a perfect candidate for this because it only depends on the .csproj files, which for the most part change infrequently (especially when compared to source code files). For a particular set of .csproj files, running dotnet restore always results in the same NuGet packages being downloaded. Package versions are explicitly specified so there’s no risk of asking for a package by name and ending up with a newer version if the package owner published an update. Docker itself cannot know for sure that this command is deterministic, but we do and can use this knowledge to invoke that step in a way that it can leverage the cache.
The .sln file is not technically necessary for dotnet restore, but it lets us execute the command once instead of doing it once per project file.
If you build the Dockerfile manually with docker build, you can actually see layer caching at play. The first time it builds, Docker will say that it’s doing work for each and every step. If you then build it again with no changes to project files nor source code, you’ll see that every step says “Using cache” (as the first image below shows). If you then change Program.cs in any way (say, adding a Console.ReadLine();), you’ll see that all steps up to the dotnet restore keep using the cache, and only subsequent commands need to be executed (as the second image below shows).

Logs from Docker build once the project has been built before.
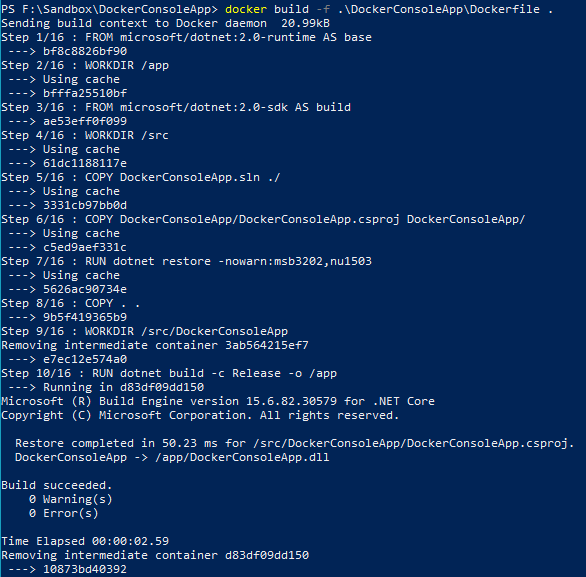
Logs from Docker build after making changes to Program.cs
So the build stage is split like that in order to maximize usage of Docker’s layer cache, and consequently minimize the time it takes to build the image. This means that Docker will only need to download your NuGet dependencies once instead of on every build.
Base stage
FROM microsoft/dotnet:2.0-runtime AS base
WORKDIR /app
Finally, we come to the base stage. I said above that it does nothing, which is basically accurate (WORKDIR does create the directory, but nothing is being copied to it). The reason why Visual Studio includes this stage in the Dockerfile it generates, is so it can work its magic to let you debug your code inside a running container. If you debug the docker-compose project, you’ll see something like these two messages in the Output window (replace with your directory and project names as necessary):
docker build -f "F:\Sandbox\DockerConsoleApp\DockerConsoleApp\Dockerfile" --target "base" -t "dockerconsoleapp:dev" "F:\Sandbox\DockerConsoleApp"
docker-compose -f "F:\Sandbox\DockerConsoleApp\docker-compose.yml" -f "F:\Sandbox\DockerConsoleApp\docker-compose.override.yml" -f "F:\Sandbox\DockerConsoleApp\obj\Docker\docker-compose.vs.debug.g.yml" -p dockercompose8626016377156038970 --no-ansi up -d --no-build --force-recreate --remove-orphans
The docker build command uses the --target parameter to indicate that Docker should stop processing the Dockerfile once it completes the steps in the base stage (and use that image as the result of the build). Since it is the first stage in the file, it’s the only one that gets built when VS is doing its magic. Visual Studio leaves this image empty because when it uses it to start a container, it will mount the directory in the host where your code lives, into the /app directory in the container. You can see how it does that by looking at the docker-compose.vs.debug.g.yml file referenced in the docker-compose command, which includes some other volumes in addition to the one that loads the source code:
volumes:
- F:\Sandbox\DockerConsoleApp\DockerConsoleApp:/app
- C:\Users\alexv\vsdbg\vs2017u5:/remote_debugger:ro
- C:\Users\alexv\.nuget\packages\:/root/.nuget/packages:ro
- C:\Program Files\dotnet\sdk\NuGetFallbackFolder:/root/.nuget/fallbackpackages:ro
Without the base stage in the Dockerfile, Visual Studio would not have an empty image to start an empty container where it could mount your source code, and would probably not be able to provide a live debugging experience when running your code inside an actual container.
Conclusion
Hopefully now you have a better understanding of why the Dockerfile generated by Visual Studio looks like it does, which should let you decide where you can safely make changes to it if you need to, while keeping it cache-friendly.